우선순위 큐란?
우선순위 큐는 정렬된 배열과 비슷한 리스트로 추상 데이터 타입의 한 예이다. 우선순위 큐 앞에서만 데이터에 접근하고 삭제하는 데 데이터를 삽입할 때는 데이터를 특정 순서대로 정렬시킨다. 우선순위 큐를 간단하게 구현하기 위해서는 아래와 같은 제약을 가진 정렬된 배열을 이용하면 된다.
- 데이터를 삽입할 때 항상 순서를 유지한다.
- 데이터는 배열의 끝에서만 삭제한다.
배열 기반 우선순위 큐는 삭제 효율성은 O(1)이고 삽입 효율성은 O(N)이다. 이러한 우선순위 큐에서 힙은 효율적으로 사용되는 자료구조이다.
힙(Heap)이란?
힙은 완전 이진 트리 (Complete Binary Tree)의 일종으로, 부모 노드와 자식 노드 간에 특정한 조건을 만족하는 자료구조를 말한다. 여기서 완전 이진 트리란 부모 노드 밑에 자식 노드가 최대 2개까지 있을 수 있고, 마지막 레벨을 제외한 모든 레벨에 노드가 완전히 채워져 있는 트리구조를 말한다. 데이터 세트에서 가장 크거나 가장 작은 데이터 원소를 계속 알아내야 할 때 유용하게 사용된다. 힙은 아래 두 가지 조건을 따른다.
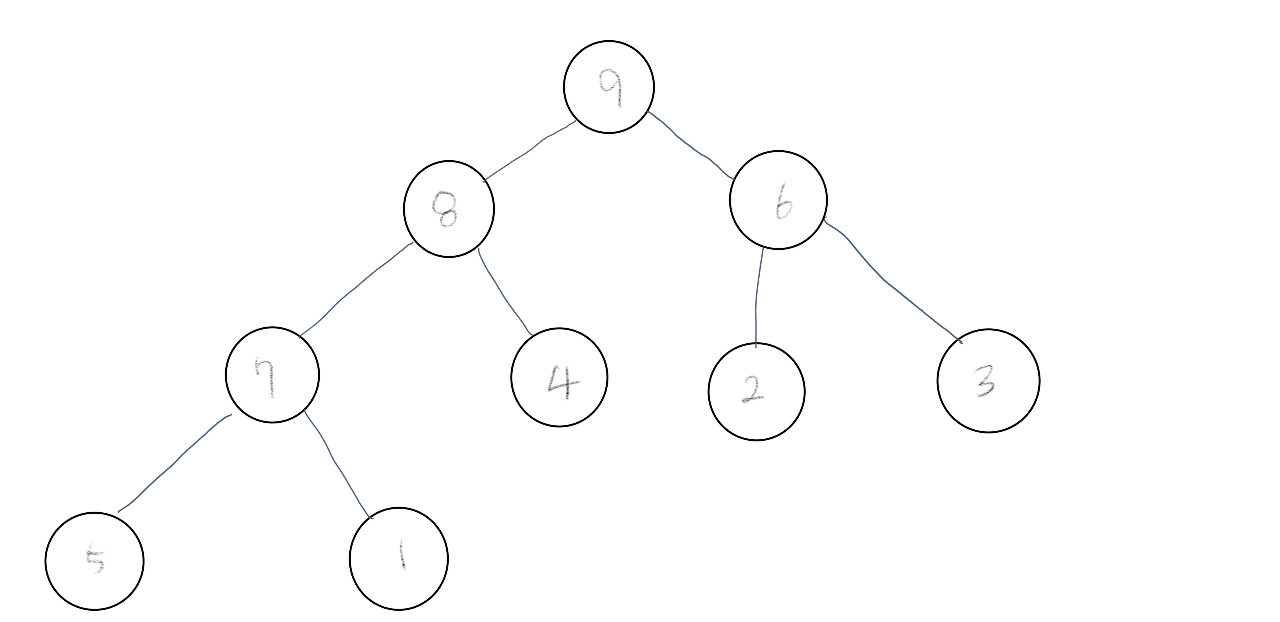
- 힙 조건
- 각 노드의 값은 그 노드의 모든 자손 노드의 값보다 커야 한다.
- 트리는 완전해야 한다
- 완전 트리는 빠진 노드 없이 노드가 완전히 채워진 트리이다.
- 트리의 각 레벨을 왼쪽으로 오른쪽으로 읽었을 때 모든 자리마다 노드가 있다. 그러나 바닥 줄에는 빈자리가 있을 수 있지만 빈자리의 오른쪽으로 어떤 노드도 없어야 한다.
📌 힙 복구 작업
힙 복구 작업은 힙 연산이 먼저 힙의 조건을 만족하지 않을 수도 있는 단순한 작업을 수행하고 힙을 순회하면서 모든 힙 영역이 힙으로서의 조건을 만족하도록 재작업하는 것이다.
- 상향식 힙 복구
- 어떤 노드가 부모 노드보다 커지면서 힙의 순서가 어긋나면 그 노드를 부모 노드와 교환해서 힙을 복구할 수 있다. 큰 키를 가진 노드가 있을 때 그 노드가 힙의 위쪽으로 거슬러 올라가면서 순서를 바로잡는다.
- 하향식 힙 복구
- 어떤 노드가 두 자식 노드들 중에 어느하나보다 작아서 힙 순서가 맞지 않는다면 그 노드를 자식 노드들 중에서 큰 노드와 교환함으로써 순서를 바로 잡을 수 있다. 노드가 차지한 위치에 비해 너무 작은 경우 힙의 아래쪽으로 내려가면서 힙의 순서를 바로잡는다.
힙 속성
- 이진 탐색 트리에 비해서 약한 정렬이다.
- 힙에는 자손이 조상보다 클 수 없다는 순서가 있지만 값을 검색하기에는 부족하기 때문이다.
- 루트 노드가 항상 최댓값이다.
- 우선순위 큐에서는 항상 가장 큰 우선순위를 갖는 값에 접근하려고 하는데 힙에서는 최댓값이 루트 노드이기 때문에 힙이 우선순위 큐를 구현하는 훌륭한 도구하고 할 수 있다.
- 주요 연산은 삽입과 삭제이다.
- 마지막 노드는 바닥 레벨에서 가장 오른쪽에 있는 노드이다.
힙 삽입 동작 순서
- 새 값을 포함하는 노드를 생성하고 바닥 레벨의 가장 오른쪽 노드 옆에 삽입한다.
- 이 값이 힙의 마지막 노드가 된다.
- 새로 삽입한 노드와 그 부모 노드를 비교한다.
- 새 노드가 부모 노드보다 크면 새 노드와 부모 노드를 스왑한다.
- 새 노드보다 큰 부모 노드를 만날 때까지 3단계를 반복하면서 새 노드를 힙 위로 올린다.
트리클링은 새 노드를 힙 위로 올리는 과정이다. 힙 삽입 효율성 노드가 N개인 이진 트리는 약 log(n)개 줄을 갖는다. 최악의 경우에는 새 값을 꼭대기 줄까지 트리클링해서 올려야 하기 때문에 힙 삽입 효율성은 O(logN)이다.
힙 삭제 동작 순서
힙에서 값을 삭제하기 위해서는 루트 노드만 삭제할 수 있다.
- 마지막 노드를 루트 노드 자리로 옮긴다.
- 루트 노드를 적절한 자리까지 아래로 트리클링한다.
- 트리클 노드의 두 자식을 확인해서 어느 쪽이 더 큰지 확인한다.
- 트리클 노드가 두 자식 노드 중 큰 노드보다 작으면 큰 노드와 트리클 노드를 교환한다.
- 두 자식 중 큰 노드를 교환하는 이유는 작은 노드와 교화하게 되면 힙 조건이 깨지기 때문이다.
- 트리클 노드에 그 노드보다 큰 자식이 없을 때까지 순서를 반복한다.
힙 삭제 효율성 루트부터 시작해서 log(N)개의 레벨을 거쳐 노드를 트리클링해야 하기 때문에 힙 삭제 효율성은 O(logN)이다.
배열로 힙 구현하기
📌 마지막 노드 찾는 법
마지막 노드를 찾을 때는 주로 배열을 사용해 힙을 구현한다. 루트 노드는 항상 인덱스 0에 저장하고 한 레벨 아래로 내려가 왼쪽에서 오른쪽 방향으로 각 노드보다 배열의 다음 인덱스를 할당한다. 이렇게 힙을 배열로 구현하면 배열의 마지막 원소는 힙의 마지막 노드가 된다.

📌 어떤 노드와 어떤 노드가 연결되어 있는지 찾는 법.
- 어떤 노드의 왼쪽 자식을 찾기 위해서는 (index*2)을 한다.
- 어떤 노드의 오른쪽 자식을 찾기 위해서는 (index*2) + 1를 한다.
📌 어떤 노드의 부모를 찾는 방법
- 어떤 노드의 부모를 찾으려면 (index-1) / 2를 하면 된다.
힙 정렬이란?
힙 정렬은 힙 구성과 정렬을 취합하는 두 단계로 이루어져 있다.
- 힙 구성
- 원본 배열을 힙으로서 재배치하는 것이다.
- 힙 구성 과정
- 배열을 왼쪽에서 오른쪽으로 순회하며 상향식 힙 복구를 이용해 순회 중인 항목의 왼쪽편이 힙 순서를 만족하는 완전 트리인지 검사하고 복구해 나간다.
- 하향식 힙 복구를 이용해 순회해 나가는 와중에 부분 힙이 생성되도록 해야 한다.
- 순회는 배열의 중간 정도에서 시작한다.
- 배열의 위치 1에서 순회가 끝나고 한 번의 힙을 내려오는 과정으로 힙 구성을 끝낸다.
- 정렬 취합
- 힙에서 내림차순으로 항목을 꺼내어 정렬된 결과를 만드는 것이다.
- 힙에 남아 있는 항목들 중에서 가장 큰 항목을 삭제하고 힙이 줄어들고 비어 있게 된 배열 위치에 집어 넣는다.
📌 힙 정렬의 효율성
힙 정렬은 시공간 측면에서 최적 성능을 보이는 유일한 알고리즘이다. 최악의 경우에서 효율성은 NlogN번의 비교횟수와 상수 크기의 추가 공간을 사용한다.
Ex.
const exchange = (array, a, b) => {
[array[a], array[b]] = [array[b], array[a]];
};
const less = (a, b) => a < b;
const sink = (array, i, N) => {
while (2 * i <= N) {
let j = 2 * i;
if (j < N && less(array[j], array[j + 1])) { // j < N 인 이유는 자식노드가 둘 다 있다는 걸 뜻함.
j++;
}
if (!less(array[i], array[j])) {
break;
}
exchange(array, i, j);
i = j;
}
};
const heapSort = (array) => {
let N = array.length - 1; // heap 정렬은 맨 앞에 비어져 있기 때문에 -1
for (let i = Math.floor(N / 2); i >= 1; i--) {
sink(array, i, N);
}
while (N > 1) {
exchange(array, 1, N);
N--;
sink(array, 1, N);
}
};'자료구조 & 알고리즘' 카테고리의 다른 글
| 알고리즘 - 퀵 정렬 (Quick Sort) / 퀵 정렬 구현 (0) | 2024.08.02 |
|---|---|
| 알고리즘 - 머지 정렬(Merge sort) / 머지 정렬 구현 (0) | 2024.08.02 |
| 알고리즘 - 셀 정렬(shell sort) / 셀 정렬 구현 (0) | 2024.08.02 |
| 알고리즘 - 삽입 정렬 (insertion sort) / 삽입 정렬 구현 (0) | 2024.08.02 |
| 알고리즘 - 선택 정렬(selection sort) / 선택 정렬 구현 (0) | 2024.08.02 |



